Original (English)
Dataset handling
The following functions can be used for downloading and parsing data from various sources, and storing
it in binary datasets.
A dataset is a list of records, normally in time descending order. Any record begins
with an 8-byte timestamp field that can also hold other 8-byte data in
special cases. The subsequent fields
have a size of 4 bytes and can contain floats, ints, or strings. The size of a record in bytes is therefore 4+fields*4.
The total number of records must not exceed the int range.
Datasets
can store option chains, order books, asset names, reports, earnings, interest
rates, or any other data organized in rows and columns. Text strings can have any size and can occupy
several adjacent fields. A
dataset can be saved, loaded, imported or exported, searched, sorted, merged,
split, resized, or used as indicator in backtests. The .t1,
.t2,
.t6, and .t8 historical data files are in fact datasets
with 1, 2, 6, or 8 data fields plus 1 timestamp field.
The following functions are used to create or load a dataset:
dataNew (int Handle, int Records, int Fields): void*
Deletes the given dataset (if any), frees the memory, and creates a new dataset with the given number of Records and Fields. If they are 0, the dataset is deleted, but no new dataset is created. Returns a pointer to the begin of the first record, or 0 when no new dataset was created.dataLoad (int Handle, string Filename, int Fields): int
Reads a dataset from a binary file. Fields is the number of fields per record, including the timestamp field at the begin of any record. Thus, a .t1 historical data file has 2 fields and a .t8 file has 9 fields. The function returns the number of records read, or 0 when the file can not be read or has a wrong size.dataCompress (int Handle, string Filename, int Fields, var Resolution): int
Like dataLoad, but reads only records that differ in at least one value other than the timestamp from the previous record, and are at least Resolution milliseconds apart. On files with 2 fields, positive and negative column 1 values are compared separately for dealing with ask and bid quotes of .t1 files. Can be used to compress price history files by changing the resolution and eliminating records with no price change.dataDownload (string Code, int Mode, int Period): int
Downloads the dataset with the given Code from QuandlT or other price sources, and stores it in CSV format in the History folder. Returns the number of data records. Data is only downloaded when it is more recent than the last downloaded data plus the given Period in minutes (at 0 the data is always downloaded). Zorro S is required for loading Quandl datasets.dataParse (int Handle, string Format, string Filename, int Start, int Num): int
Parses a part or all data records from the CSV file Filename and appends them at the start of the dataset with the given Handle number. For beginning a new dataset when content was already parsed, call dataNew(Handle,0,0) before. Num records are parsed, beginning with the record Start. If both parameters are omitted or zero, the whole CSV file is parsed.Records can have time/date, floating point, integer, and text fields. CSV headers are skipped. Several CSV files can be appended to the same dataset when their record format is identical. The CSV file can be in ascending or descending chronological order, but the resulting dataset should normally be in descending order, i.e. the newest records are at the begin. Any record in the dataset begins with a time stamp field in DATE format; the other fields can be in arbitrary order determined by the Format string (see Parameters). If the CSV file does not contain time stamps, the first field in the record is filled with zero.
The function returns the number of records read, or 0 when the file can not be read or has a wrong format. Please see below under Remarks how to build a correct format string and how to debug the parsing.
dataParse (int Handle, string Format, string Filename, string Filter): int
As before, but parses only lines that contain the string Filter. The string is case sensitive and can include delimiters, so it can cover several adjacent fields. Use delimiters at begin and end for matching a whole field. Use '\n' as first filter character for matching the first field. This way only lines with a certain asset name, year number, or other content are parsed.dataParseJSON (int Handle, string Format, string Filename): int
dataParseString (int Handle, string Format, string Content): int
As before, but parses timestamp, prices, and volumes from the JSON file Filename (with ".json" extension) or from the given JSON string to the dataset with the given Handle number. The file or string is supposed to contain OHLC candles or BBO quotes as JSON objects in winged brackets {..}. Depending on Format (see Parameters), the dataset is created either in T6 record format with 7 fields, or in T2 format with 3 fields. The field names are given with the Format string in a fixed order. Data fields in the JSON file must contain valid numbers; they must not be empty or contain text like "NaN" or "null". Content is modified by the parsing process.The function returns the number of records read, or 0 when the file can not be read or has a wrong format.Storing datasets
dataSave (int Handle, string Filename, int Start, int Num)
Stores the dataset with the given Handle as a binary file. Num records are stored, beginning with the record Start. If both parameters are omitted or zero, the whole dataset is stored. Make sure that the number of records does not exceed the 2,147,483,647 limit and the resulting file size does not exceed 5 GB, which is the Windows limit for file operations.dataSaveCSV (int Handle, string Format, string Filename, int Start, int Num)
The opposite to dataParse; stores a part or all of the dataset with the given Handle number in a CSV file with the given FileName. The type and order of the CSV fields can be defined by the Format string in the same way as for dataParse, except that no header line is stored. Usage example in CSVfromHistory.c.Manipulating datasets
dataMerge (int Handle1, int Handle2): int
Merges dataset Handle2 into dataset Handle1. Both datasets must be sorted in descending time stamp order, and the first dataset must begin with an earlier timestamp than the second. When timestamps overlap, the content from the second dataset replaces content from the first. This function can be used to stitch datasets together. Returns the total number of records, or 0 when the datasets could not be merged.dataAppend (int Handle1, int Handle2, int Start, int Num): int
Appends dataset Handle2 partially or completely at the end of the dataset Handle1. The Handle1 dataset must be either empty or have the same number of columns as Handle2. The number of rows may be different. Num records from Handle2 are stored, beginning with the record Start. If both parameters are omitted or zero, the whole dataset is appended. Returns the total number of records, or 0 when the datasets could not be appended.dataAppendRow (int Handle, int Fields): void*
Appends a new record at the end of the given dataset, and returns a temporary pointer to the begin of the new record. If the dataset didn't exist, it is created with the given number of fields. The returned pointer remains valid until the next dataAppendRow call. Use dataRow (see below) for converting the pointer to a record number.dataDelete (int Handle, int Record1, int Record2): int
Deletes all records from Record1 up to Record2 from the dataset. Returns its new number of records.dataClip (int Handle, int Records): int
Truncates the dataset to the given number of records.dataSort (int Handle)
Sorts the dataset with the given Handle in descending order of the first column (usually the time stamp). If Handle is negative, sorts in ascending order. Returns the number of records.dataCompressSelf (int Handle, var MinTime)
Like dataCompress, but compresses the dataset with the given Handle.Plotting datasets
Datasets can be plotted to a histogram or statistics chart with the plot commands. For plotting them in special ways, the following commands have been added:
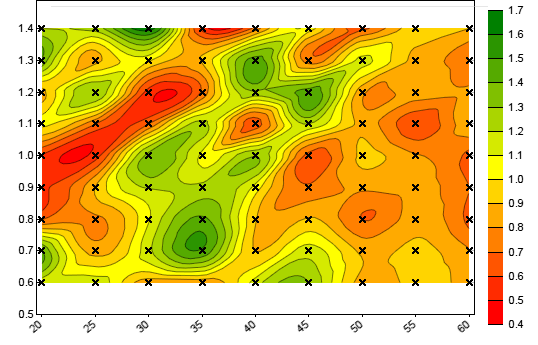
dataChart (int Handle, string Filename, CONTOUR, NULL)
Generates a contour chart of a 3-field dataset. The resulting image is stored under Filename when PL_FILE is set, otherwise displayed on the interactive chart. The value in the first field of a record is displayed as a contour color ranging from red to green. The second field is the x coordinate and the third field the y coordinate (see example). CONTOUR|DOT plots a cross at every xy coordinate. This function can be used to display parameter contour charts from CSV files exported by genetic or brute force training.dataChart (int Handle, string Filename, HEATMAP, NULL)
Generates a heatmap from a 2D dataset. The resulting image is stored under Filename when PL_FILE is set, otherwise displayed on the interactive chart. The dataset contains heat values in a column x row matrix that are displayed in colors ranging from blue to red. This function can be used to display correlation or weight heatmaps.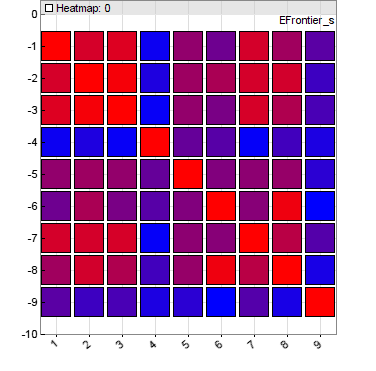
Accessing data
dataFind (int Handle, var Date): int
Returns the number of the first record at or before the given Date in wdate format. Returns -1 when no matching record was found or when no dataset with the given Handle exists. Returns the number of records when Date is 0. The dataset must be in descending time stamp order. Decrease the returned record number to retreive records with later dates; increase it to get records with earlier dates or with the same date. Subtract an offset from Date for avoiding future peeking; f.i. for EOD datasets with timestamps from the begin and data from the end of the day, subtract 16 hours (16./24) to adjust the timestamps to 16:00 market close time.dataRow (int Handle, void *Record): int
Returns the row number of the record with the given pointer. Reverse function of dataStr(Handle,Row,0).dataSize (int Handle, int *Rows, int *Columns): int
Returns the number of elements in the given dataset, and set the Rows and Columns pointers, when nonzero, to the number of records and fields.dataSet (int Handle, int Row, int Column, var Value)
dataSet (int Handle, int Row, int Column, int Value)
Stores the Value in the floating point or integer field Column of the record Row. Can be used for modifying datasets f.i. for removing outliers or adding parameters. Since the target field format depends on whether Value is int or var, make sure to use the correct type, especially when entering constants, and typecast it with (int) or (var) if in doubt. When modifying the time stamp field of the record (Column = 0), make also sure to keep descending order of dates in the array.dataVar (int Handle, int Row, int Column): var
Returns the value of the floating point field Column from the record Row. If Column is 0, the time stamp of the record is returned in wdate format. If Row is negative, the record is taken from the end of the dataset, i.e. Row = -1 accesses the oldest record. If the dataset is empty or if Row or Column exceed the number of records and fields, 0 is returned.dataInt (int Handle, int Row, int Column): int
As before, but returns the value of the integer field Column from the record Row.dataStr (int Handle, int Row, int Column): string
As before, but returns a pointer to the field Column from the record Row. It it's a text field, the text string of up to 3, 7, or 11 characters is returned. If Column is 0, it returns a pointer to the timestamp field, i.e. the start of the record. For getting a pointer to the first record of the dataset, call dataStr(Handle,0,0). For modifying a text field in a dataset, return its string pointer and then modify the string.dataCol (int Handle, var* Data, int Column): int
Sets the predefined rMin, rMax, rMinIdx and rMaxIdx variables to the minimum and maximum values of the given Column. If Data is nonzero, fills it with all float or double elements from the column. The Data array must have at least the same number of elements than the number of records in the dataset. Returns the number of records.dataCopy (int Handle, var* Data): int
Fills the Data array with the content of the dataset, while all float elements are converted to double. Sets the rMin and rMax variables to the minimum and maximum value. Returns the number of elements. The Data array must have at least the same number of elements as the dataset.Helper functions
dataFromQuandl (int Handle, string Format, string Code, int Column): var
Helper function for generating an indicator based on a QuandlT EOD time series. Works in live trading as well as in backtest mode, and returns the content of the field Column from the dataset Code in the given Format. This function is often used for getting extra market data, such as the yield rate or the Commitment of Traders (COT) report of particular assets. Timestamps are automatically adjusted by 16 hours so that the indicator changes when the US market opens. If this is not desired, remove the term -16./24 from the function source code in contract.c (which must be included for using this function). Zorro S is required for accessing Quandl data.dataFromCSV (int Handle, string Format, string Filename, int Column, int Offset): var
Helper function for generating an indicator based on a downloaded CSV file; for backtesting only. Returns the content of the field Column from the file Filename.csv in the given Format. Offset is the time stamp adjustment in minutes, f.i. to 16:00 for avoiding future peeking with EOD data. Source code in contract.c, which must be included for using this function.Parameters:
| Code | The Google or Quandl code, f.i. "NYSE:AMZN" or "WIKI/AAPL". For selecting a ticker from a Quandl data table, add a colon and the ticker symbol, f.i. "ZACKS/ES:AAPL". The file is stored in the History folder under the Code name with ": /' characters replaced with "- _", plus "1" when only the most recent record was downloaded, plus ".csv". |
| Mode | FROM_GOOGLE for downloading a time series from GoogleT FROM_GOOGLE|1 for downloading only the last records, for live trading FROM_QUANDL for downloading a time series from QuandlT (Zorro S and Quandl key required). FROM_QUANDL|1 for downloading only the most recent record, for live trading FROM_QTABLE for downloading a QuandlT data table |
| Period | Minimum time in minutes to keep the last downloaded file until a newer file is downloaded, or 0 for always downloading the file. |
| Handle | A number from 1...1000 that identifies the dataset. Handles above 1000 are reserved for Zorro functions. |
| FileName | Name of the file, with relative or absolute path. |
| Records | Number of records in the dataset. |
| Fields | Number of fields per record, including the date field. |
| Date | Timestamp in Windows DATE format. Days are represented by whole number increments starting with 30 December 1899, midnight UTC. The time of the day is represented in the fractional part of the number. |
| Start, Num | The first record and the number of records to be stored. |
| Row, Column | The record and field number, starting with 0. The date is always the first field of the record. If Row is negative, the record is taken from the end of the file, i.e. Row = -1 accesses the oldest record. |
| Value | New value of the addressed field. |
| Filter | Filter string to select lines to be parsed. The line must contain the string. Use delimiters for matching a complete field. Use '\n' as first character when the line must begin with the filter string. |
| Format |
CSV format string for parsing records with mixed content from a CSV file to a dataset, or for storing a dataset to a file in the CSV format. Fields in the format string are separated with the same delimiter as in the CSV file, either a comma, a semicolon, or '|' for a tab. A field can be either empty, or contain a placeholder that determines the field content. Fields with no placeholder are skipped and don't appear in the dataset. A record of a CSV time series should contain at least one date/time field; if there are more, f.i. separate fields for date and time, they are summed up. Codes at the begin of the format string: + - ascending date order; reverse the records and append
parsed data to the end of the dataset.
Otherwise descending date order is assumed and data is appended to the
begin. The following placeholders can be used to parse field content. If the format string is empty or contains no placeholders, the CSV file is parsed as if all fields contained floating point numbers. f - for a floating point field, f.i. 123.456.
If the delimiter is a semicolon, the decimal point can be a comma. Date/time fields are parsed into field 0 of the dataset and can be retrieved with dataVar(..,..,0) in the Windows DATE format. The number of fields in the dataset is the date field plus the sum of all f, i, s characters in the format string. It can be different to the number of fields in the CSV record. The f, i, s placeholders are normally followed by a field number in the resulting dataset. Example: "+%Y%m%d %H%M%S,f3,f1,f2,f4,f6" parses HistdataT CSV files into a dataset in T6 format. If the field number is omitted, the fields are parsed in ascending order, starting with field 0. Use f1 for starting with field 1. Skipped fields are filled with 0. |
| Format | JSON format string containing the token names of a OHLC candle or
ask/bid (BBO) quote in a JSON file. OHLC candles are stored in T6 records,
ask or bid quotes are stored in T2 records. T6: "Start,Time,Timeformat,High,Low,Open,Close,AdjClose,Volume" T2: "Start,Time,Timeformat,Ask,AskSize,Bid,BidSize" Start - token name or start string of the whole price structure. Determines from where to parse. Timeformat - format of the date/time field with DATE format codes, as in the CSV format string. Time - token name of the date/time field. High,Low,Open,Close - token names of the price fields. AdjClose - token name of the adjusted close field, or empty if the file contains no such field. Volume - token name of the volume field, or empty if the file contains no volume data. Ask - token name of the best ask quote field. AskSize - token name of the ask size field. Bid - token name of the best bid quote field, or empty if the file contains no bid quotes. BidSize - token name of the bid size field, or empty. If the file already begins with the '[' character, use it for the start token. Example: "[,date,%t,high,low,open,close,,". |
Remarks:
- An easy way to generate the Format string is copying a line from the CSV file to the script as a format template, then editing its fields. Replace the year number with %Y, the month with %m, the day with %d, the hour with %H, the minute with %M, the second with %S. Replace prices with f, integer numbers or expiration dates with i, and text with s, ss, or sss, dependent on the maximum string length. Delete the content of unused fields, but leave the delimiters. Add numbers to the placeholders when their fields in the target dataset are in a different order than in the CSV file (the header file trading.h contains the field numbers for often used structs). For instance, in a dataset in T6 format, the Open is the third price (f3), High is first (f1), Low is second (f2), Close is 4th (f4), and Volume is sixth (f6). Finally, append +, 0, or 2 to the begin of the resulting string dependent on date order and number of header lines. Now you have the correct Format string for parsing the file.
- For checking the correct parsing, set Verbose to 7. The first two lines of the first CSV file are then printed to the log and message window, and their parsed versions below them. If your format string is so wrong that nothing is parsed at all, you'll get Error 058 instead. For checking the correct parsing further, the resulting dataset can be saved to a CSV file with dataSaveCSV.
- For parsing extremely large CSV files, set Verbose to 2 or above. Zorro will then print a dot for every 1,000,000 parsed lines. If the resulting dataset does not fit in 32-bit memory, use the 64-bit Zorro version and a .cpp file for parsing.
- If you cannot determine the correct format string for parsing a complex file, Zorro support can help. For a fistful of EUR you can also order a conversion script (check out the support page under "Services"). Many example scripts for data parsing and conversion can also be found under Import.
- Numbers in CSV files must not exceed the float range. Only straight decimal numbers can be imported. Hex, binary, octal, or scientific notation with appended exponent is not supported.
- If dataDownload failed due to a wrong code or for other reasons, the target file usually contains the error message from the service.
- The historical data files are simply datasets with 2, 3, 7, or 9 fields in descending timestamp order. They all can be loaded with dataLoad. The record format is defined in include\trading.h.
- Converting exotic CSV files to a specific dataset format, such as .t6 or .t8, requires often a 2-step process. In the first step, the CSV file is parsed into a temporary dataset. In the second step, the dataset is converted with a script that loops through all records and modifies fields to their final format. Examples of this can be found in the conversion scripts.
- When loading indicators from EOD data, be aware that the time stamp is usually from the begin of the day (00:00), while the data is from the end of the day (16:00). For avoiding future peeking, shift the dataFind time back by 16 hours, or use a 16*60 minutes offset with dataFromCSV.
- For loading data from Quandl (Zorro S required), register on www.quandl.com and enter your received Quandl API key in the Zorro.ini file.
- For speed reasons, full historical data arrays should be only loaded in the initial run of the system. While live trading, use FROM_QUANDL|1 or FROM_GOOGLE|1 for downloading the most recent data record only (see example).
- The size of a record in bytes is (Fields+1)*4. The size of the whole data area is therefore Records*(Fields+1)*4. Field 0 with the timestamp has a size of 8 bytes, the other fields have a size of 4 bytes. The number of records can be determined with dataFind(Handle,0).
- For storing complex data such as structs, use a sufficient record size plus 8 bytes for the timestamp, and copy the struct to dataStr(Handle,Record,1). If a separate timestamp is not needed, or if it is part of the struct as for the T1..T8 structs, the struct can be stored to dataStr(Handle,Record,0).
- For selecting a dataset not with its handle number, but with a string - for instance an asset name - use the stridx / strxid functions.
- For splitting extremely large CSV files into smaller parts, use free tools such as CSVSplitter for Windows.
Examples (see also import, scripts, and contract):
// COT report for S&P500
var CFTC_SP(int Column) {
return dataFromQuandl(802,"%Y-%m-%d,f,f,f,f,f,f,f,f,f,f,f,f,f,f,f,f,f","CFTC/TIFF_CME_SP_ALL",Column);
}
// convert some .csv formats to .t6
string Format = "%Y-%m-%d,f3,f1,f2,f4,,,f6,f5"; // Quandl futures format to .t6, f.i. "CHRIS/CME_CL1"
dataParse(1,Format,"History\\CL1.csv");
dataSave(1,"History\\CL1.t6");
string Format = "%Y-%m-%d,f3,f1,f2,f4,f6,f5"; // Yahoo data format to unadjusted .t6, with adjusted close stored in fVal
dataParse(1,Format,"History\\history.csv");
dataSave(1,"History\\AAPL.t6");
// read a time series out of field 1 of dataset H
vars MyData = series(dataVar(H,dataFind(H,wdate(0)),1));
// Coinbase Bitcoin/EUR price to .t1
void main()
{
string Format = "+0,,,%t,f,f,s";
int Records = dataParse(1,Format,"History\\BTCEUR.csv");
printf("\n%d records read",Records);
// now convert it to t1 and change sign for sell quotes
for(i=0; itime = dataVar(1,i,0);
t1->fVal = dataVar(1,i,1);
string sell = dataStr(1,i,3);
if(sell[0] == 't') t1->fVal = -t1->fVal;
// display progress bar and check [Stop] button
if(!progress(100*i/Records,0)) break;
}
if(Records) dataSave(2,"History\\BTCEUR.t1");
}
// evaluate an extra parameter stored with time stamps in a dataset
...
if(Init) dataLoad(1,"History\\MyParameters.dta",2);
int Row = dataFind(1,wdate(0));
MyExtraParameter = dataVar(1,Row,1);
...
// Download earnings data from AlphaVantage
// and store earnings surprises in a dataset
int loadEarnings()
{
string URL = strf("https://www.alphavantage.co/query?function=EARNINGS&symbol=%s&apikey=%s",
Asset,report(33)); // 33 = AlphaVantage API key
string Content = http_transfer(URL,0); // JSON format
if(!Content) return 0;
string Pos = strstr(Content,"reportedDate");
if(!Pos) return 0;
dataNew(1,0,0);
while(Pos) {
var Date = wdatef("%Y-%m-%d",Pos+12+4);
if(Date == 0) break;
Pos = strstr(Pos,"surprisePercentage");
if(!Pos) break;
int Row = dataRow(1,dataAppendRow(1,2));
dataSet(1,Row,0,Date); // earnings date in field 0
dataSet(1,Row,1,atof(Pos+18+4)); // surprise in field 1
printf("\n%.4f %.4f",dataVar(1,Row,0),dataVar(1,Row,1));
Pos = strstr(Pos,"reportedDate"); // next JSON record
}
return 1;
}
// plot a heatmap
void main()
{
dataNew(1,8,10);
int i,j;
for(i=0; i<8; i++)
for(j=0; j<10; j++)
dataSet(1,i,j,(var)(i+j));
dataChart(1,"Test",HEATMAP,NULL);
}
// plot a contour map
void main()
{
dataNew(1,100,3);
int i,j;
for(i=0; i<10; i++)
for(j=0; j<10; j++) {
dataSet(1,i*10+j,2,(var)i);
dataSet(1,i*10+j,1,(var)j);
dataSet(1,i*10+j,0,(var)(i+j));
}
dataChart(1,"Test",CONTOUR|DOT,NULL);
}
// plot the 2nd field of a dataset as a red line
int Records = dataLoad(1,"MyDataset.dta");
int N;
for(N=0; N
See also:
file, strvar,
sortData, price history, contract
► latest
version online
Übersetzung (Deutsch)
Dataset-Verarbeitung
Die folgenden Funktionen können verwendet werden, um Daten aus verschiedenen Quellen herunterzuladen und zu parsen sowie
sie in binären Datasets zu speichern.
Ein Dataset ist eine Liste von Datensätzen, normalerweise in zeitlich absteigender Reihenfolge. Jeder Datensatz beginnt
mit einem 8-Byte-Zeitstempelfeld, das in Spezialfällen auch andere 8-Byte-Daten enthalten kann. Die nachfolgenden Felder
haben eine Größe von 4 Byte und können Floats, Ints oder Strings enthalten. Die Größe eines Datensatzes in Bytes beträgt daher 4+fields*4.
Die Gesamtanzahl der Datensätze darf den int-Bereich nicht überschreiten.
Datasets
können Optionsketten, Orderbücher, Asset-Namen, Berichte, Gewinne, Zinssätze oder beliebige andere Daten speichern, die in Zeilen und Spalten organisiert sind. Textstrings können beliebig groß sein und mehrere benachbarte Felder belegen.
Ein Dataset kann gespeichert, geladen, importiert oder exportiert, durchsucht, sortiert, zusammengeführt,
geteilt, in der Größe angepasst oder als Indikator in Backtests verwendet werden. Die historischen Datenformate .t1,
.t2,
.t6 und .t8 sind in Wirklichkeit Datasets
mit 1, 2, 6 oder 8 Datenfeldern plus 1 Zeitstempelfeld.
Die folgenden Funktionen dienen zum Erstellen oder Laden eines Datasets:
dataNew (int Handle, int Records, int Fields): void*
Löscht das angegebene Dataset (falls vorhanden), gibt den Speicher frei und erstellt ein neues Dataset mit der angegebenen Anzahl Records und Fields. Wenn beide Werte 0 sind, wird das Dataset gelöscht, aber kein neues angelegt. Gibt einen Zeiger auf den Beginn des ersten Datensatzes zurück oder 0, wenn kein neues Dataset erstellt wurde.dataLoad (int Handle, string Filename, int Fields): int
Liest ein Dataset aus einer Binärdatei. Fields ist die Anzahl Felder pro Datensatz, einschließlich des Zeitstempelfelds am Anfang jedes Datensatzes. Daher hat eine .t1-Historiendatei 2 Felder und eine .t8-Datei hat 9 Felder. Die Funktion gibt die Anzahl gelesener Datensätze zurück oder 0, wenn die Datei nicht gelesen werden kann oder eine falsche Größe aufweist.dataCompress (int Handle, string Filename, int Fields, var Resolution): int
Ähnlich wie dataLoad, liest jedoch nur Datensätze ein, die sich in mindestens einem Wert (außer dem Zeitstempel) vom vorherigen Datensatz unterscheiden und mindestens Resolution Millisekunden auseinanderliegen. Bei Dateien mit 2 Feldern werden positive und negative Werte von Spalte 1 getrennt verglichen, um mit Ask- und Bid-Quotes von .t1-Dateien umzugehen. Kann verwendet werden, um Preis-Historien zu komprimieren, indem die Auflösung geändert und alle Datensätze ohne Kursänderung entfernt werden.dataDownload (string Code, int Mode, int Period): int
Lädt das Dataset mit dem angegebenen Code von QuandlT oder anderen Preisquellen herunter und speichert es im CSV-Format im History-Ordner. Gibt die Anzahl der Datenzeilen zurück. Daten werden nur heruntergeladen, wenn sie aktueller sind als die zuletzt heruntergeladenen Daten plus die angegebene Period in Minuten (bei 0 wird die Datei immer heruntergeladen). Zorro S ist erforderlich, um Quandl-Datasets zu laden.dataParse (int Handle, string Format, string Filename, int Start, int Num): int
Liest einen Teil oder alle Datensätze aus der CSV-Datei Filename und hängt sie an den Anfang des Datasets mit dem angegebenen Handle an. Um ein neues Dataset zu beginnen, wenn bereits Inhalte geparst wurden, rufen Sie vorher dataNew(Handle,0,0) auf. Num Datensätze werden eingelesen, beginnend beim Datensatz Start. Wenn beide Parameter weggelassen oder 0 sind, wird die gesamte CSV-Datei geparst.Datensätze können Zeit-/Datumsfelder, Gleitkommawerte, Integer und Text enthalten. CSV-Header werden übersprungen. Mehrere CSV-Dateien können demselben Dataset hinzugefügt werden, wenn ihr Datensatzformat identisch ist. Die CSV-Datei kann in auf- oder absteigender chronologischer Reihenfolge vorliegen, das resultierende Dataset sollte jedoch normalerweise in absteigender Reihenfolge sein, d. h. die neuesten Datensätze stehen am Anfang. Jeder Datensatz im Dataset beginnt mit einem Zeitstempelfeld im DATE-Format; die anderen Felder können in einer beliebigen Reihenfolge vorliegen, die durch den Format-String (siehe Parameters) bestimmt wird. Wenn die CSV-Datei keine Zeitstempel enthält, wird das erste Feld im Datensatz mit Null gefüllt.
Die Funktion gibt die Anzahl der gelesenen Datensätze zurück oder 0, wenn die Datei nicht gelesen werden kann oder das Format falsch ist. Unter Remarks weiter unten wird beschrieben, wie Sie einen korrekten Format-String erstellen und das Parsing debuggen können.
dataParse (int Handle, string Format, string Filename, string Filter): int
Wie zuvor, aber parst nur Zeilen, die den String Filter enthalten. Der String ist groß-/kleinschreibungssensitiv und kann Delimiter enthalten, sodass er mehrere benachbarte Felder abdecken kann. Verwenden Sie Delimiter zu Beginn und Ende, um ein ganzes Feld abzugleichen. Verwenden Sie '\n' als erstes Zeichen des Filters, um das erste Feld abzugleichen. So werden nur Zeilen mit einem bestimmten Asset-Namen, einer Jahreszahl oder einem anderen Inhalt geparst.dataParseJSON (int Handle, string Format, string Filename): int
dataParseString (int Handle, string Format, string Content): int
Wie zuvor, jedoch werden Zeitstempel, Preise und Volumina aus der JSON-Datei Filename (mit ".json"-Endung) oder aus dem übergebenen JSON-String in das Dataset mit der angegebenen Handle-Nummer eingelesen. Die Datei oder der String soll OHLC-Kerzen oder BBO-Quotes als JSON-Objekte in geschweiften Klammern {..} enthalten. Abhängig vom Format (siehe Parameters) wird das Dataset entweder im T6-Format mit 7 Feldern oder im T2-Format mit 3 Feldern angelegt. Die Feldnamen werden durch den Format-String in einer festen Reihenfolge vorgegeben. Datenfelder in der JSON-Datei müssen gültige Zahlen enthalten; sie dürfen nicht leer sein oder Text wie "NaN" oder "null" enthalten. Content wird durch den Parsing-Vorgang modifiziert. Die Funktion gibt die Anzahl der gelesenen Datensätze zurück oder 0, wenn die Datei nicht gelesen werden kann oder das Format falsch ist.Speichern von Datasets
dataSave (int Handle, string Filename, int Start, int Num)
Speichert das Dataset mit dem angegebenen Handle als Binärdatei. Num Datensätze werden gespeichert, beginnend mit Datensatz Start. Wenn beide Parameter weggelassen oder 0 sind, wird das gesamte Dataset gespeichert. Achten Sie darauf, dass die Anzahl der Datensätze 2.147.483.647 nicht überschreitet und die resultierende Dateigröße nicht 5 GB überschreitet, da dies die Windows-Grenze für Dateioperationen ist.dataSaveCSV (int Handle, string Format, string Filename, int Start, int Num)
Das Gegenstück zu dataParse; speichert einen Teil oder das gesamte Dataset mit der angegebenen Handle-Nummer in eine CSV-Datei mit dem angegebenen FileName. Der Typ und die Reihenfolge der CSV-Felder können über den Format-String definiert werden, genau wie bei dataParse, nur dass keine Kopfzeile gespeichert wird. Beispiel für die Verwendung in CSVfromHistory.c.Bearbeiten von Datasets
dataMerge (int Handle1, int Handle2): int
Führt Dataset Handle2 in Dataset Handle1 ein. Beide Datasets müssen in absteigender Zeitstempelreihenfolge sortiert sein, und das erste Dataset muss mit einem früheren Zeitstempel als das zweite beginnen. Wenn sich Zeitstempel überschneiden, werden Inhalte aus dem zweiten Dataset in das erste übernommen. Diese Funktion kann verwendet werden, um Datasets zusammenzufügen. Gibt die Gesamtanzahl an Datensätzen zurück oder 0, wenn die Datasets nicht zusammengeführt werden konnten.dataAppend (int Handle1, int Handle2, int Start, int Num): int
Hängt Dataset Handle2 teilweise oder vollständig ans Ende des Datasets Handle1 an. Das Handle1-Dataset muss entweder leer sein oder dieselbe Spaltenanzahl wie Handle2 besitzen. Die Zeilenanzahl kann abweichen. Num Datensätze aus Handle2 werden übernommen, beginnend bei Datensatz Start. Wenn beide Parameter weggelassen oder 0 sind, wird das gesamte Dataset angehängt. Gibt die Gesamtanzahl an Datensätzen zurück oder 0, wenn die Datasets nicht angehängt werden konnten.dataAppendRow (int Handle, int Fields): void*
Fügt am Ende des angegebenen Datasets einen neuen Datensatz an und gibt einen temporären Zeiger auf den Anfang des neuen Datensatzes zurück. Wenn das Dataset nicht existierte, wird es mit der angegebenen Anzahl Felder erstellt. Der zurückgegebene Zeiger bleibt gültig bis zum nächsten Aufruf von dataAppendRow. Verwenden Sie dataRow (siehe unten), um den Zeiger in eine Datensatznummer umzuwandeln.dataDelete (int Handle, int Record1, int Record2): int
Löscht alle Datensätze von Record1 bis Record2 aus dem Dataset. Gibt die neue Anzahl der Datensätze zurück.dataClip (int Handle, int Records): int
Kürzt das Dataset auf die angegebene Anzahl Datensätze.dataSort (int Handle)
Sortiert das Dataset mit dem angegebenen Handle in absteigender Reihenfolge anhand der ersten Spalte (üblicherweise der Zeitstempel). Wenn Handle negativ ist, wird in aufsteigender Reihenfolge sortiert. Gibt die Anzahl der Datensätze zurück.dataCompressSelf (int Handle, var MinTime)
Ähnlich wie dataCompress, jedoch komprimiert das Dataset mit dem angegebenen Handle.Plotten von Datasets
Datasets können mit den plot-Befehlen als Histogramm oder Statistikdiagramm dargestellt werden. Für spezielle Darstellungen wurden folgende Befehle hinzugefügt:
dataChart (int Handle, string Filename, CONTOUR, NULL)
Erzeugt ein Contour-Diagramm aus einem Dataset mit 3 Feldern. Das resultierende Bild wird unter Filename gespeichert, wenn PL_FILE gesetzt ist, ansonsten wird es im interaktiven Chart angezeigt. Der Wert im ersten Feld eines Datensatzes wird als Contour-Farbe angezeigt, die von Rot bis Grün reicht. Das zweite Feld ist die x-Koordinate und das dritte Feld die y-Koordinate (siehe Beispiel). CONTOUR|DOT zeichnet ein Kreuz an jede xy-Koordinate. Diese Funktion kann verwendet werden, um Parameter-Contour-Diagramme aus CSV-Dateien darzustellen, die durch genetisches oder brute-force-Training exportiert wurden.dataChart (int Handle, string Filename, HEATMAP, NULL)
Erzeugt eine Heatmap aus einem 2D-Dataset. Das resultierende Bild wird unter Filename gespeichert, wenn PL_FILE gesetzt ist, ansonsten wird es im interaktiven Chart angezeigt. Das Dataset enthält Heat-Werte in einer Spalten-×-Zeilen-Matrix, die in Farben von Blau bis Rot angezeigt werden. Diese Funktion kann verwendet werden, um Korrelations- oder Gewichtungs-Heatmaps darzustellen. Zugriff auf Daten
dataFind (int Handle, var Date): int
Gibt die Nummer des ersten Datensatzes zum oder vor dem angegebenen Date im wdate-Format zurück. Gibt -1 zurück, wenn kein entsprechender Datensatz gefunden wurde oder kein Dataset mit dem angegebenen Handle existiert. Gibt die Anzahl der Datensätze zurück, wenn Date 0 ist. Das Dataset muss in absteigender Zeitstempelreihenfolge vorliegen. Verringern Sie die zurückgegebene Datensatznummer, um Datensätze mit späteren Daten abzurufen; erhöhen Sie sie, um Datensätze mit früheren oder demselben Datum abzurufen. Subtrahieren Sie einen Offset von Date, um Future-Peeking zu vermeiden; z. B. für EOD-Datasets mit Zeitstempeln vom Tagesanfang und Daten vom Tagesende ziehen Sie 16 Stunden (16./24) ab, um die Zeitstempel auf 16:00 Uhr (Marktschluss) anzupassen.dataRow (int Handle, void *Record): int
Gibt die Zeilennummer des Datensatzes mit dem angegebenen Zeiger zurück. Umkehrfunktion von dataStr(Handle,Row,0).dataSize (int Handle, int *Rows, int *Columns): int
Gibt die Anzahl Elemente des angegebenen Datasets zurück und setzt die Zeiger Rows und Columns, falls ungleich 0, auf die Anzahl Datensätze bzw. Felder.dataSet (int Handle, int Row, int Column, var Value)
dataSet (int Handle, int Row, int Column, int Value)
Schreibt den Wert Value in das Gleitkomma- oder Integer-Feld Column des Datensatzes Row. Kann zum Beispiel zum Bearbeiten von Datasets verwendet werden, um Ausreißer zu entfernen oder Parameter hinzuzufügen. Da das Zielfeldformat davon abhängt, ob Value vom Typ int oder var ist, achten Sie darauf, den richtigen Typ zu verwenden, insbesondere beim Eingeben von Konstanten; casten Sie sie im Zweifelsfall mit (int) oder (var). Wenn Sie das Zeitstempelfeld des Datensatzes (Column = 0) ändern, achten Sie darauf, die absteigende Reihenfolge der Zeitstempel im Array beizubehalten.dataVar (int Handle, int Row, int Column): var
Gibt den Wert des Gleitkommafelds Column im Datensatz Row zurück. Ist Column = 0, wird der Zeitstempel des Datensatzes im wdate-Format zurückgegeben. Ist Row negativ, wird der Datensatz vom Ende des Datasets genommen, also greift Row = -1 auf den ältesten Datensatz zu. Wenn das Dataset leer ist oder Row bzw. Column die Anzahl der Datensätze und Felder übersteigen, wird 0 zurückgegeben.dataInt (int Handle, int Row, int Column): int
Wie zuvor, jedoch wird der Wert des Integer-Felds Column aus dem Datensatz Row zurückgegeben.dataStr (int Handle, int Row, int Column): string
Wie zuvor, jedoch wird ein Zeiger auf das Feld Column aus dem Datensatz Row zurückgegeben. Handelt es sich dabei um ein Textfeld, wird der Textstring von bis zu 3, 7 oder 11 Zeichen zurückgegeben. Wenn Column = 0 ist, wird ein Zeiger auf das Zeitstempelfeld zurückgegeben, d. h. auf den Beginn des Datensatzes. Um einen Zeiger auf den ersten Datensatz des Datasets zu erhalten, rufen Sie dataStr(Handle,0,0) auf. Um ein Textfeld in einem Dataset zu ändern, holen Sie sich den string-Zeiger und ändern anschließend den Text.dataCol (int Handle, var* Data, int Column): int
Setzt die vordefinierten Variablen rMin, rMax, rMinIdx und rMaxIdx auf die Minimal- und Maximalwerte der angegebenen Spalte Column. Wenn Data ungleich 0 ist, füllt sie alle float- oder double-Elemente aus der Spalte hinein. Das Array Data muss mindestens so viele Elemente haben wie das Dataset Datensätze. Gibt die Anzahl der Datensätze zurück.dataCopy (int Handle, var* Data): int
Füllt das Array Data mit den Inhalten des Datasets, während alle float-Elemente in double umgewandelt werden. Setzt die Variablen rMin und rMax auf die Minimal- bzw. Maximalwerte. Gibt die Anzahl der Elemente zurück. Das Array Data muss mindestens so viele Elemente besitzen wie das Dataset.Hilfsfunktionen
dataFromQuandl (int Handle, string Format, string Code, int Column): var
Hilfsfunktion zum Erstellen eines Indikators basierend auf einer QuandlT-EOD-Zeitreihe. Funktioniert sowohl im Live-Trading als auch im Backtest und gibt den Inhalt des Felds Column aus dem Dataset Code im angegebenen Format zurück. Diese Funktion wird häufig zum Abrufen zusätzlicher Marktdaten wie Renditeraten oder des Commitment of Traders (COT)-Berichts bestimmter Assets verwendet. Zeitstempel werden automatisch um 16 Stunden verschoben, damit sich der Indikator ändert, wenn der US-Markt öffnet. Wenn dies nicht gewünscht ist, entfernen Sie den Ausdruck -16./24 aus dem Funktionscode in contract.c (das eingebunden werden muss, um diese Funktion zu verwenden). Zorro S ist für den Zugriff auf Quandl-Daten erforderlich.dataFromCSV (int Handle, string Format, string Filename, int Column,int Offset): var
Hilfsfunktion zum Erstellen eines Indikators auf Basis einer heruntergeladenen CSV-Datei; nur für Backtests. Gibt den Inhalt des Felds Column aus der Datei Filename.csv im angegebenen Format zurück. Offset ist die Zeitstempel-Anpassung in Minuten, z.B. 16:00, um Future-Peeking bei EOD-Daten zu vermeiden. Der Quellcode befindet sich in contract.c, das eingebunden werden muss, um diese Funktion zu verwenden.Parameter:
| Code | Der Google- oder Quandl-Code, z.B. "NYSE:AMZN" oder "WIKI/AAPL". Zum Auswählen eines Tickers aus einer Quandl-Datentabelle fügen Sie einen Doppelpunkt und das Tickersymbol hinzu, z.B. "ZACKS/ES:AAPL". Die Datei wird im History-Ordner unter dem Code-Namen gespeichert, wobei ": /'-Zeichen durch "- _" ersetzt werden, plus "1", wenn nur der neueste Datensatz heruntergeladen wurde, plus ".csv". |
| Mode | FROM_GOOGLE zum Herunterladen einer Zeitreihe von GoogleT FROM_GOOGLE|1 zum Herunterladen nur der letzten Datensätze, für Live-Trading FROM_QUANDL zum Herunterladen einer Zeitreihe von QuandlT (Zorro S und Quandl key erforderlich). FROM_QUANDL|1 zum Herunterladen nur der neuesten Datensätze, für Live-Trading FROM_QTABLE zum Herunterladen einer QuandlT-Datentabelle |
| Period | Minimale Zeit in Minuten, um die zuletzt heruntergeladene Datei zu behalten, bevor eine neuere Datei heruntergeladen wird, oder 0, um die Datei immer herunterzuladen. |
| Handle | Eine Nummer aus dem Bereich 1...1000, die das Dataset identifiziert. Handles über 1000 sind für Zorro-Funktionen reserviert. |
| FileName | Der Name der Datei, mit relativem oder absolutem Pfad. |
| Records | Anzahl der Datensätze im Dataset. |
| Fields | Anzahl der Felder pro Datensatz, einschließlich des Datumsfelds. |
| Date | Zeitstempel im Windows-DATE-Format. Tage werden durch ganzzahlige Inkremente ab dem 30. Dezember 1899 (UTC Mitternacht) dargestellt. Die Tageszeit wird im Nachkommateil der Zahl gespeichert. |
| Start, Num | Der erste zu speichernde Datensatz und die Anzahl der Datensätze. |
| Row, Column | Datensatz- und Feldnummer, beginnend mit 0. Das Datum steht immer im ersten Feld. Ist Row negativ, wird der Datensatz vom Ende der Datei genommen, d.h. Row = -1 greift auf den ältesten Datensatz zu. |
| Value | Neuer Wert des angesprochenen Felds. |
| Filter | Filter-String zum Auswählen der zu parsenden Zeilen. Die Zeile muss den String enthalten. Verwenden Sie Delimiter für das exakte Abgleichen eines Felds. Verwenden Sie '\n' als erstes Zeichen, wenn die Zeile mit dem Filterstring beginnen soll. |
| Format |
CSV-Format-String zum Parsen von Datensätzen mit gemischten Inhalten aus einer CSV-Datei in ein Dataset oder zum Speichern eines Datasets in eine CSV-Datei. Felder im Format-String sind durch dasselbe Trennzeichen getrennt wie in der CSV-Datei - entweder ein Komma, ein Semikolon oder '|' für einen Tabulator. Ein Feld kann entweder leer sein oder einen Platzhalter enthalten, der den Feldinhalt bestimmt. Felder ohne Platzhalter werden übersprungen und erscheinen nicht im Dataset. Ein Datensatz einer CSV-Zeitreihe sollte mindestens ein Datums-/Zeitfeld enthalten; wenn es mehr gibt, z.B. getrennte Felder für Datum und Zeit, werden sie addiert. Codes am Anfang des Format-Strings: + - aufsteigende Datumsreihenfolge; kehrt die Datensätze um und hängt die geparsten Daten ans Ende des Datasets.
Andernfalls wird eine absteigende Datumsreihenfolge angenommen und Daten werden am Anfang angefügt. Die folgenden Platzhalter können verwendet werden, um Feldinhalte zu parsen. Wenn der Format-String leer ist oder keine Platzhalter enthält, wird die CSV-Datei geparst, als ob alle Felder Gleitkommazahlen enthielten. f - für ein Gleitkommafeld, z.B. 123.456.
Wenn das Trennzeichen ein Semikolon ist, kann das Dezimaltrennzeichen ein Komma sein. Datums-/Zeitfelder werden in Feld 0 des Datasets geparst und können mit dataVar(..,..,0) im Windows-DATE-Format abgefragt werden. Die Anzahl Felder im Dataset besteht aus dem Datumsfeld plus der Summe aller f, i, s-Platzhalter im Format-String. Sie kann sich von der Anzahl der Felder im CSV-Datensatz unterscheiden. Die Platzhalter f, i, s werden normalerweise von einer Feldnummer im resultierenden Dataset gefolgt. Beispiel: "+%Y%m%d %H%M%S,f3,f1,f2,f4,f6" parst HistdataT-CSV-Dateien in ein Dataset im T6-Format. Wenn die Feldnummer weggelassen wird, werden die Felder in aufsteigender Reihenfolge geparst, beginnend mit Feld 0. Verwenden Sie f1, um mit Feld 1 zu beginnen. Übersprungene Felder werden mit 0 gefüllt. |
| Format | JSON-Format-String, der die Token-Namen einer OHLC-Kerze oder
Ask-/Bid-(BBO)-Quote in einer JSON-Datei enthält. OHLC-Kerzen werden in T6-Datensätzen gespeichert,
Ask- oder Bid-Quotes werden in T2-Datensätzen gespeichert. T6: "Start,Time,Timeformat,High,Low,Open,Close,AdjClose,Volume" T2: "Start,Time,Timeformat,Ask,AskSize,Bid,BidSize" Start - Token-Name oder Start-String der gesamten Preisstruktur. Bestimmt, ab wo geparst wird. Timeformat - Format des Datums-/Zeitfeldes mit DATE-Formatcodes wie im CSV-Format-String. Time - Token-Name des Datums-/Zeitfeldes. High,Low,Open,Close - Token-Namen der Preisfelder. AdjClose - Token-Name des angepassten Schlussfeldes oder leer, wenn die Datei kein solches Feld enthält. Volume - Token-Name des Volumenfeldes oder leer, wenn die Datei kein Volumen enthält. Ask - Token-Name für das beste Ask-Quote-Feld. AskSize - Token-Name für das Ask-Size-Feld. Bid - Token-Name für das beste Bid-Quote-Feld oder leer, wenn kein Bid-Quote enthalten ist. BidSize - Token-Name für das Bid-Size-Feld oder leer. Wenn die Datei bereits mit dem Zeichen '[' beginnt, verwenden Sie dieses als Start-Token. Beispiel: "[,date,%t,high,low,open,close,,". |
Anmerkungen:
- Ein einfacher Weg, um den Format-String zu erstellen, besteht darin, eine Zeile aus der CSV-Datei als Formatvorlage in das Skript zu kopieren und sie dann entsprechend anzupassen. Ersetzen Sie Jahreszahl, Monat, Tag, Stunde, Minute, Sekunde jeweils durch %Y, %m, %d, %H, %M, %S. Ersetzen Sie Preise durch f, Integer oder Fälligkeitsdaten durch i, sowie Text durch s, ss oder sss, abhängig von der maximalen Zeichenlänge. Löschen Sie den Inhalt nicht benötigter Felder, lassen Sie jedoch die Trennzeichen stehen. Fügen Sie Zahlen zu den Platzhaltern hinzu, wenn deren Felder im Zieldataset in einer anderen Reihenfolge vorliegen als in der CSV-Datei (die Headerdatei trading.h enthält Feldnummern für häufig verwendete Strukturen). In einem Dataset im T6-Format ist zum Beispiel das Open der dritte Preis (f3), High der erste (f1), Low der zweite (f2), Close der vierte (f4) und Volume der sechste (f6). Fügen Sie abschließend ein +, 0 oder 2 an den Anfang des resultierenden Strings hinzu, je nach Datumsreihenfolge und Anzahl Headerzeilen. So erhalten Sie den richtigen Format-String zum Parsen der Datei.
- Um das richtige Parsing zu prüfen, setzen Sie Verbose auf 7. Die ersten zwei Zeilen der ersten CSV-Datei werden dann ins Log- und Nachrichtenfenster gedruckt und darunter ihre geparsten Versionen. Wenn Ihr Format-String so falsch ist, dass gar nichts geparst wird, erhalten Sie Error 058. Um das Parsing weiter zu prüfen, kann das resultierende Dataset mit dataSaveCSV in eine CSV-Datei gespeichert werden.
- Für das Parsen extrem großer CSV-Dateien setzen Sie Verbose auf 2 oder höher. Zorro druckt dann für jeweils 1.000.000 gelesene Zeilen einen Punkt. Wenn das resultierende Dataset nicht in den 32-Bit-Speicher passt, verwenden Sie die 64-Bit-Zorro-Version und eine .cpp-Datei für das Parsing.
- Falls Sie keinen passenden Format-String für eine komplexe Datei bestimmen können, hilft der Zorro-Support. Für eine Handvoll EUR können Sie auch ein Konvertierungsskript beauftragen (siehe Support-Seite unter "Services"). Viele Beispielscripte zum Daten Parsen und Konvertieren finden sich außerdem unter Import.
- Zahlen in CSV-Dateien dürfen den Float-Bereich nicht überschreiten. Nur normale Dezimalzahlen können importiert werden. Hex-, Binär-, Oktal- oder wissenschaftliche Notation mit angehängtem Exponenten wird nicht unterstützt.
- Wenn dataDownload wegen eines falschen Codes oder aus anderen Gründen fehlschlägt, enthält die Zieldatei meist die Fehlermeldung des Dienstes.
- Die historischen Datendateien sind einfach Datasets mit 2, 3, 7 oder 9 Feldern in absteigender Zeitstempelreihenfolge. Sie können alle mit dataLoad geladen werden. Das Datensatzformat ist in include\trading.h definiert.
- Das Konvertieren exotischer CSV-Dateien in ein bestimmtes Dataset-Format, wie .t6 oder .t8, erfordert oft einen 2-stufigen Prozess. Im ersten Schritt wird die CSV-Datei in ein temporäres Dataset geparst. Im zweiten Schritt wird dieses Dataset mithilfe eines Skripts konvertiert, das alle Datensätze durchläuft und deren Felder ins Zielformat ändert. Beispiele hierfür finden Sie in den Konvertierungsskripten.
- Wenn Indikatoren aus EOD-Daten geladen werden, beachten Sie, dass der Zeitstempel normalerweise vom Tagesbeginn (00:00) ist, während die Daten vom Tagesende (16:00) stammen. Um Future-Peeking zu vermeiden, verschieben Sie die dataFind-Zeit um 16 Stunden nach hinten oder verwenden einen 16*60-minütigen Offset mit dataFromCSV.
- Um Daten von Quandl zu laden (Zorro S erforderlich), registrieren Sie sich auf www.quandl.com und tragen Sie Ihren erhaltenen Quandl-API-Key in die Zorro.ini-Datei ein.
- Aus Performancegründen sollten vollständige historische Datenarrays nur im Initialdurchlauf des Systems geladen werden. Während des Live-Tradings verwenden Sie FROM_QUANDL|1 oder FROM_GOOGLE|1, um nur den neuesten Datensatz herunterzuladen (siehe Beispiel).
- Die Größe eines Datensatzes in Bytes beträgt (Fields+1)*4 . Die Gesamtgröße des gesamten Datenbereichs beträgt daher Records*(Fields+1)*4. Feld 0 mit dem Zeitstempel ist 8 Bytes groß, die anderen Felder jeweils 4 Bytes. Die Anzahl der Datensätze kann mit dataFind(Handle,0) ermittelt werden.
- Um komplexe Daten wie Strukturen zu speichern, verwenden Sie eine ausreichende Datensatzgröße zuzüglich 8 Byte für den Zeitstempel und kopieren die Struktur in dataStr(Handle,Record,1). Wenn kein separater Zeitstempel benötigt wird oder er Teil der Struktur ist (wie bei den T1.. T8-Strukturen), kann die Struktur in dataStr(Handle,Record,0) gespeichert werden.
- Um ein Dataset nicht über seine Handle-Nummer, sondern per String auszuwählen - z.B. einen Asset-Namen -, verwenden Sie die Funktionen stridx / strxid.
- Um extrem große CSV-Dateien in kleinere Teile zu splitten, verwenden Sie freie Tools wie CSVSplitter für Windows.
Beispiele (siehe auch import, scripts und contract):
// COT-Bericht für S&P500
var CFTC_SP(int Column) {
return dataFromQuandl(802,"%Y-%m-%d,f,f,f,f,f,f,f,f,f,f,f,f,f,f,f,f,f","CFTC/TIFF_CME_SP_ALL",Column);
}
// einige .csv-Formate zu .t6 konvertieren
string Format = "%Y-%m-%d,f3,f1,f2,f4,,,f6,f5"; // Quandl-Futures-Format zu .t6, z.B. "CHRIS/CME_CL1"
dataParse(1,Format,"History\\CL1.csv");
dataSave(1,"History\\CL1.t6");
string Format = "%Y-%m-%d,f3,f1,f2,f4,f6,f5"; // Yahoo-Datenformat zu nicht adjustiertem .t6, mit Adjusted Close in fVal
dataParse(1,Format,"History\\history.csv");
dataSave(1,"History\\AAPL.t6");
// Zeitreihe aus Spalte 1 des Datasets H lesen
vars MyData = series(dataVar(H,dataFind(H,wdate(0)),1));
// Coinbase Bitcoin/EUR-Kurs zu .t1
void main()
{
string Format = "+0,,,%t,f,f,s";
int Records = dataParse(1,Format,"History\\BTCEUR.csv");
printf("\n%d records read",Records);
// jetzt zu t1 konvertieren und Vorzeichen für Sell-Quotes ändern
for(i=0; itime = dataVar(1,i,0);
t1->fVal = dataVar(1,i,1);
string sell = dataStr(1,i,3);
if(sell[0] == 't') t1->fVal = -t1->fVal;
// Fortschrittsbalken anzeigen und [Stop]-Button prüfen
if(!progress(100*i/Records,0)) break;
}
if(Records) dataSave(2,"History\\BTCEUR.t1");
}
// Einen zusätzlichen Parameter laden, der mit Zeitstempeln in einem Dataset gespeichert ist
...
if(Init) dataLoad(1,"History\\MyParameters.dta",2);
int Row = dataFind(1,wdate(0));
MyExtraParameter = dataVar(1,Row,1);
...
// Earnings-Daten von AlphaVantage herunterladen
// und Earnings-Surprises in einem Dataset speichern
int loadEarnings()
{
string URL = strf("https://www.alphavantage.co/query?function=EARNINGS&symbol=%s&apikey=%s",
Asset,report(33)); // 33 = AlphaVantage API key
string Content = http_transfer(URL,0); // JSON-Format
if(!Content) return 0;
string Pos = strstr(Content,"reportedDate");
if(!Pos) return 0;
dataNew(1,0,0);
while(Pos) {
var Date = wdatef("%Y-%m-%d",Pos+12+4);
if(Date == 0) break;
Pos = strstr(Pos,"surprisePercentage");
if(!Pos) break;
int Row = dataRow(1,dataAppendRow(1,2));
dataSet(1,Row,0,Date); // Earnings-Datum in Feld 0
dataSet(1,Row,1,atof(Pos+18+4)); // Surprise in Feld 1
printf("\n%.4f %.4f",dataVar(1,Row,0),dataVar(1,Row,1));
Pos = strstr(Pos,"reportedDate"); // nächster JSON-Eintrag
}
return 1;
}
// Heatmap zeichnen
void main()
{
dataNew(1,8,10);
int i,j;
for(i=0; i<8; i++)
for(j=0; j<10; j++)
dataSet(1,i,j,(var)(i+j));
dataChart(1,"Test",HEATMAP,NULL);
}
// Contour-Karte zeichnen
void main()
{
dataNew(1,100,3);
int i,j;
for(i=0; i<10; i++)
for(j=0; j<10; j++) {
dataSet(1,i*10+j,2,(var)i);
dataSet(1,i*10+j,1,(var)j);
dataSet(1,i*10+j,0,(var)(i+j));
}
dataChart(1,"Test",CONTOUR|DOT,NULL);
}
// Die zweite Spalte eines Datasets als rote Linie plotten
int Records = dataLoad(1,"MyDataset.dta");
int N;
for(N=0; N
Siehe auch:
file, strvar,
sortData, price history, contract
► neueste
Version online